遞迴語言模型 (RLM):讓 LLM 突破上下文限制的革命性方法
本文整理自 MIT CSAIL 團隊發表的論文《Recursive Language Models》(arXiv:2512.24601),作者為 Alex L. Zhang、Tim Kraska 與 Omar Khattab。
論文連結:https://arxiv.org/html/2512.24601v1
GitHub 專案:https://github.com/alexzhang13/rlm
核心問題:上下文窗口的瓶頸
大型語言模型(LLM)有一個根本性的限制:上下文窗口。即使是最先進的模型,也只能處理有限長度的輸入。當你需要分析一本書、處理大量程式碼庫、或是回答需要整合海量資訊的問題時,這個限制就成了巨大的障礙。
傳統的解決方案包括:擴展上下文窗口、使用 RAG(檢索增強生成)、或是摘要策略。但這些方法各有缺陷——擴展窗口成本高昂,RAG 可能遺漏關鍵資訊,摘要則會損失細節。
MIT 團隊提出了一個優雅的解決方案:讓 LLM 自己決定如何處理超長輸入。
什麼是遞迴語言模型(RLM)?
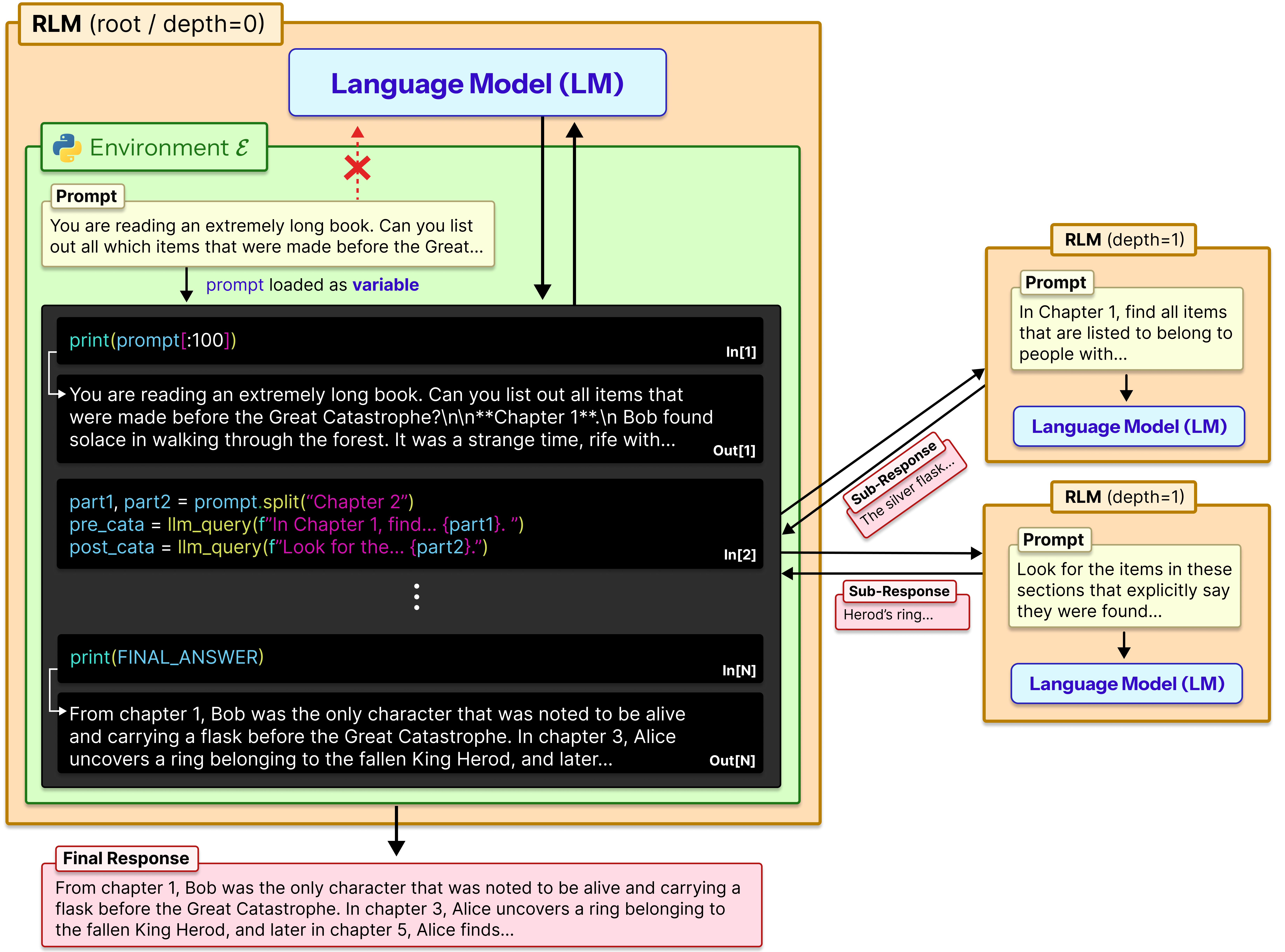
RLM 是一種全新的推理策略。核心概念很簡單:與其把整個超長輸入直接塞進模型,不如讓模型在一個 Python REPL 環境中,透過程式碼來「探索」輸入。
想像你是一個研究員,面對一本 1000 頁的書要找答案。你不會從頭讀到尾,而是:
- 先看目錄,了解結構
- 根據問題定位相關章節
- 深入閱讀關鍵段落
- 如果需要,再細分成更小的部分處理
RLM 讓 AI 也能這樣做。
RLM 的運作機制
在 RLM 框架下:
-
輸入成為環境變數:超長的輸入文本被存放在 Python 環境中,模型可以透過程式碼存取
-
模型撰寫探索程式碼:模型可以用 regex 搜尋、切片、過濾等方式,找出需要的資訊片段
-
遞迴自我呼叫:當遇到複雜問題時,模型可以把子問題「外包」給自己的另一個實例處理
-
程式碼執行與整合:所有探索的結果透過程式執行產生,最後整合成答案
這就像是給了 AI 一套工具箱,讓它自己決定怎麼使用,而不是被動地一次吃進所有資訊。
驚人的實驗結果
研究團隊在多個基準測試上評估 RLM,結果令人印象深刻:
處理能力大幅提升
- RLM 能處理超過 1000 萬 tokens 的輸入——這是原本模型上下文窗口的 100 倍以上
- 在相同成本下,效能提升最高達 2 倍
在複雜任務上的表現
以 OOLONG-Pairs 測試為例(需要在大量資訊中找出配對關係):
- 傳統 LLM:準確率 < 0.1%
- RLM:準確率 23-58%
這不是微幅改進,而是從「幾乎不可能」變成「實際可用」的質變。
成本效益
RLM 的成本隨任務複雜度呈 對數線性 增長,而非隨輸入長度線性增長。這意味著處理超長輸入時,RLM 反而更經濟。
模型學會的有趣策略
研究者觀察到模型在使用 RLM 時,自發發展出幾種有趣的策略:
1. Regex 過濾
模型會寫正則表達式來快速篩選相關內容,而不是逐字閱讀。這展現了模型「知道如何偷懶」的智慧。
2. 均勻切分
面對需要分解的任務,模型傾向於把輸入均勻切成若干塊,而非嘗試「聰明地」找切分點。簡單粗暴,但有效。
3. 答案驗證
有時模型會透過遞迴呼叫來「雙重檢查」自己的答案,雖然這有時會引入冗餘,但也提高了可靠性。
RLM 的實際應用
這個框架已經開源,你可以直接使用:
from rlm import RLM
rlm = RLM(
backend="openai",
backend_kwargs={"model_name": "gpt-5-nano"},
verbose=True
)
# 處理超長輸入
result = rlm.completion("分析這份 500 頁的報告,找出所有關於氣候變遷的政策建議")
print(result.response)支援的功能:
- 多種 LLM 後端(OpenAI、Anthropic、OpenRouter 等)
- 多種執行環境(本地、Docker、Modal 雲端沙箱)
- 執行軌跡視覺化工具
限制與未來方向
研究者誠實地指出幾個限制:
- 最佳實作尚未探索完全:目前的 RLM 可能還不是最優解
- 執行效率可提升:非同步呼叫可以大幅減少執行時間
- 專門訓練的潛力:如果專門訓練模型成為 RLM,效果可能更好
為什麼這很重要?
RLM 代表了一種思維轉變:從「擴大模型胃口」轉向「讓模型學會消化」。
這不只是工程上的改進,更是對 AI 能力邊界的重新定義。當 AI 能夠自主決定如何處理資訊,而不是被動接收,它就更接近真正的智慧。
想像未來的應用場景:
- 律師 AI 分析數十萬頁的案例文獻
- 研究 AI 綜述整個學科領域的論文
- 程式 AI 理解並重構百萬行級別的程式碼庫
這些過去看似不可能的任務,現在有了實現的路徑。
結語
RLM 展示了一個簡單但深刻的洞見:讓 AI 用程式碼思考。
當我們給予 AI 工具和自主權,而不是試圖塞給它所有資訊,它能展現出驚人的適應性和創造力。這或許也是通往更強大 AI 系統的關鍵路徑之一。
如果你對這個領域感興趣,強烈建議去看看原始論文和 GitHub 專案,動手實驗看看。
延伸資源
- 論文:https://arxiv.org/html/2512.24601v1
- GitHub:https://github.com/alexzhang13/rlm
- 作者 Twitter:@alexzhang13